|
The 1990s
witnessed an explosion in the growth of the Internet. The number of
connected networks and users has increased dramatically, posing the
threat of address space exhaustion. Meanwhile, a new sort of
application appeared, characterized by real-time constraints and
driven by the emergence of cheap digital multimedia technology,
which puts significant new communication demands on the underlying
networks. This has set a considerable challenge for the Internet,
which was designed to support non-time-critical applications.
Besides requiring an increase in network capacity (i.e., the
communications bandwidth), some significant architectural
enhancements were prompted as well.
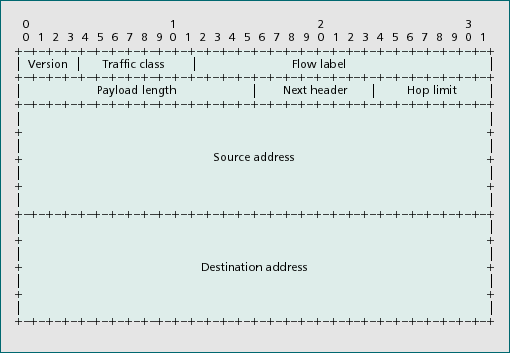
Figure 1 - The
IPv6 header format
This has
triggered the birth of new protocols such as multicast (leading to
the creation of the MBone), Classless Interdomain Routing (CIDR),
RSVP, and Real-Time Transport Protocol (RTP). The features of the
current version of the IP layer, IPv4, have been able to underpin
these protocols for the past few years. However, it became evident
that a more uniform and fundamentally better adapted solution to the
new requirements was needed to provide a smooth evolution of the
network.
IPv6 was then
designed and adopted as the successor to IPv4, to occupy, of course,
the central place in the entire Internet protocol architecture. As
with IPv4, IPv6 is still based on the key concept of a datagram. On
the other hand, IPv6 exhibits the following changes from its
predecessor:
·
Expanded address capabilities:
IPv6 uses 16-byte-long addresses; these extend the CIDR addressing
hierarchy strategy and definitively overcome the scaling problem of
IPv4 (which uses 4-byte-long addresses).
·
New packet format:
The packets are based on a simple header (Fig.1). Also, the way
header options are encoded has been totally rethought.
·
Multicast support:
IPv6 supports multicast as a native communication mode. Moreover,
the addition of a scope field to multicast addresses improves the
scalability of multicast routing.
·
Flow labeling capability:
This allows a sender to identify packets as being related to one
another (i.e., belonging to the same traffic flow).
·
Anycast support:
Anycast is used to send a packet to any one member of a group of
receivers (supposedly the "closest" in terms of the routing
algorithm's unit of measurement).
·
Authentication and privacy capabilities.
It is interesting
to note how optional Internet-layer information is encoded in IPv6.
Indeed, those options are encoded in separate headers that may be
placed between the IPv6 header and the upper-layer header in the
packet. Such headers are called extension headers, each identified
by a distinct "next header" value Fig. 1). As a consequence, the
"complete" header of an IPv6 packet can actually be seen as a
"chain" of headers starting with the basic IPv6 header Fig. 1) and
followed by some (i.e., zero or more) extension headers.
So far, six
extension headers have been defined:
·
Hop-by-hop options header:
Carries information that has to be examined and processed by each
node on the packet's path, with the source and destination included.
·
Routing header:
Used by a source to list one or more routers to be visited by the
packet en route to its destination. This is very similar to IPv4's
source route option.
·
Fragment header:
Used when fragmentation is required. In IPv6, fragmentation can only
be done at the source.
·
Destination header:
Used to carry information that needs to be examined and processed by
the destination of the packet.
·
Authentication header and encapsulation security payload header.
New extension
headers can be defined if required.
Finally, we note
that the traffic class field in Fig. 1 is labeled the Differentiated
Services (DS) field in the DiffServ work.
The experience
gained during the years of operating and evolving IPv4 is reflected
in IPv6 through the incorporation of some very interesting design
features.
By supporting
multicast as a native communication mode, IPv6 takes a decisive step
toward avoiding the problems of bandwidth consumption exhibited by
the MBone. Indeed, due to its implementation using tunnels between
multicast routers (i.e., encapsulation of multicast packets in IPv4
packets), the MBone tends to replicate, several times, the same
packet on its links. This is because a packet is replicated a number
of times equal to the number of tunnels using the link. By avoiding
the use of tunnels for multicasting (because multicast is
"integrated" in the protocol), IPv6 will improve the support of
multicast in the Internet. This will only happen when most of the
routers in the Internet are based on IPv6, avoiding the need for
tunneling IPv6 through IPv4 routes.
Besides better
multicast routing, IPv6 also offers a very useful feature to improve
control of multicast traffic: the scope field added to the multicast
addresses. This allows precise control of where multicast packets
are sent, and is very useful to avoid "leaks" of multicast packets
on the Internet as well as ensure some security (e.g., making sure
that a remote site cannot eavesdrop on a local teleconference). The
same functionality can be obtained on the MBone today, but at the
price of a difficult tuning of the IPv4 time to live (TTL) field.
Also, the native support for anycast makes resource discovery a lot
easier.
The IPv6 (basic)
header format is simpler than that in IPv4. Indeed, some of the IPv4
header fields have been dropped (e.g., the header checksum) or made
optional (e.g., fragmentation). This can only be beneficial to the
performance achieved by IPv6, since the common-case processing cost
(i.e., CPU instructions) of packet handling is reduced. In other
words, packet forwarding is more efficient with IPv6.
Because of the
simplification of the IPv6 header, a new way to deal with options
had to be devised. This resulted in the extension headers already
described. The good point about extension headers is that they allow
less stringent limits on options than those imposed by IPv4 due to a
lack of space in the IPv4 header. This is the case, for instance,
with the source routing option which, in IPv4, limits the
specification of the route to a maximum of nine hops. In IPv6 the
limitation is 24 hops.
Fragmentation is
a costly operation. Not only does it increase the overhead
associated with the fragmented packet (because of the "replication"
of the header in each fragment), but it also requires significant
processing time at the fragmenting/reassembling nodes. By
restricting fragmentation to being performed by source nodes only,
IPv6 thus offloads the burden of fragmenting from potentially
heavily loaded routers. It is worth noting that, given the
widespread use of Ethernet LANs, this can lead to a network where it
is unlikely to encounter packets bigger than 1500 bytes.
The flow labeling
capability allows flow identification without layer violation (i.e.,
without combining fields from different protocol headers, e.g., IP
and UDP headers). This not only enables fine-grained flow
identification, but also simplifies the treatment of flows where
security issues may require payload encryption at the network (i.e.,
IP) layer. Flow labeling also has an important role in QoS support
since QoS in a network should be closely linked to the concept of
flow (at least at the edge of the network). This is because QoS as
required by multimedia communications cannot be defined on a
datagram basis.
Although we
acknowledge that extension headers were introduced for flexibility
when dealing with options as well as getting rid of most of IPv4's
limitations, the whole idea of extension headers nonetheless
introduces concerns. Since new extension headers as well as new
options for each of the existing headers can be specified at any
time, it seems almost impossible to design routers that will process
all the extensions efficiently. Indeed, when a new extension or
option is introduced, the only reasonable way to make an existing
router understand it is by means of a software update. This,
however, contradicts the trend to build high-speed routers using
specialized hardware.
Furthermore,
since each new extension or option will impose updates on routers'
and end systems' software, we may find there is disparity from one
node to another, since some will be updated and others not. Such
disparity in the functions supported in the nodes may well render
some of those extensions or options totally unusable (because the
nodes will either discard or misprocess packets containing options
or extensions they do not understand). At best, we may evolve toward
a situation where most of the nodes in the Internet will only
support the core extension headers and options specified in today's
version of the IPv6 specification.
A summary of the
two previous paragraphs is perhaps to say that extended systems are
probably better than extensible ones, especially when considering
large-scale networks.
The IPv6
specification says that "with one exception (the hop-by-hop option
header), extension headers are not examined or processed by any node
along a packet's delivery path, until the packet reaches the node
identified in the destination address field of the IPv6 header." We
would like to mention that when routing options are used (i.e.,
source routing), the destination of a packet changes several times
on the way to the final destination, which will trigger the
processing of the extension headers in the "intermediate"
destination (i.e., routers). This may cause the corresponding packet
to experience very long transmission delays.
It is worth
noting that the concept of flow seems to somewhat contradict the
concept of datagrams, and that simultaneous support for flows and
datagrams by the same packet type inevitably leads to unnecessary
overhead. When forwarding a packet in "datagram mode," the routers
ignore the flow label. When forwarding a packet in "flow mode" (by
ensuring that the different packets of a flow receive the same
treatment from the network), a router should ignore the destination
and source addresses of the packet. This is illustrated by the
example of a telephone-quality audio flow (64 kb/s) where one packet
is sent every 20 ms. Assuming now the typical use of RTP/UDP/IP for
media transfer in the Internet, the header "information" would
comprise 60 bytes (40 bytes of IPv6 header, 8 bytes of UDP header,
and 12 bytes of RTP header); the packet payload would be 160 bytes.
We would therefore have a per-packet overhead of about 27 percent,
of which 53 percent is IPv6 addresses and 5 percent is the flow
label.
With regard to
the treatment packets of a given flow should receive, the IPv6
specification is rather elusive, stating that routers may (and thus
may not) use flow labels to treat packets. It therefore appears that
a source using a flow label will have no guarantee that the
corresponding packets will receive special attention from the
network. In other words, it cannot be assumed that IPv6 provides a
communication scheme where the concept of flow has significance
throughout the network (i.e., for nodes other than the source and
destination).
The features of
IPv6 (address size, packet format, etc.) render it incompatible with
IPv4. In other words, in spite of the similarities in their name,
IPv6 and IPv4 are two different protocols unable to interoperate.
Therefore, a transition mechanism has had to be devised to
facilitate and encourage the deployment of IPv6. This transition
mechanism roughly specifies that:
·
Each IPv6 router or end system has to provide a complete
implementation of both versions (IPv4 and IPv6). This leads to a
dual-stack architecture in every IPv6 node.
·
IPv6 traffic will, when necessary, be carried over the IPv4 routing
infrastructure using a tunneling technique (i.e., encapsulation of
the IPv6 packets into IPv4 ones). This is likely to ruin the
advantages of native support for multicast communication.
Finally, current
Internet transport protocols (i.e., TCP and UDP) include the
addresses from the IP header in their checksum computation. Since
the size of IPv6 addresses is different from those of IPv4, these
transport protocols have to be modified.
|




